Learning to detect mobile objects from lidar scans without labels

Video still of the technology. Credit: Ryan Young/Cornell University.
AUTONOMOUS driving promises to revolutionise how we transport goods, travel, and interact with our environment. To safely plan a route, a self-driving vehicle must first perceive and localise mobile traffic participants such as other vehicles and pedestrians in 3D.
Current state-of-the-art 3D object detectors are all based on deep neural networks and can yield up to 80 average precision on benchmark datasets.
However, as with all deep learning approaches, these techniques have an insatiable need for labelled-data. Specifically, to train a 3D object detector that takes lidar scans as input, one typically needs to first come up with a list of objects of interest and annotate each of them with tight bounding boxes in the 3D point cloud space.
Such a data annotation process is laborious and costly, but worst of all, the resulting detectors only achieve high accuracy when the training and test data distributions match. In other words, their accuracy deteriorates over time and space, as looks and shapes of cars, vegetation, and background objects change. To guarantee good performance, one has to collect labelled training data for specific geo-fenced areas and re-label data constantly, greatly limiting the applicability and development of self-driving vehicles.
These problems motivate the question: Can we learn a 3D object detector from unlabelled lidar data? Here, we focus on ‘mobile’ objects, i.e. objects that might move, which cover a wide range of traffic participants. At first glance, this seems insurmountably challenging. After all, how could a detector know just from the lidar point cloud that a pedestrian is a traffic participant and a tree is not?
We tackle this problem with the help of two important insights:
- We can use simple heuristics that, even without labelling, can occasionally distinguish traffic participants from background objects more or less reliably.
- If data is noisy but diverse, neural networks excel at identifying the common patterns, allowing us to repeatedly self-label the remaining objects, starting from a small set of seed labels.
Weak labels through heuristics
We build upon a simple yet highly generalisable concept to discover mobile objects – mobile objects are unlikely to stay persistent at the same location over time. While this requires unlabelled data at multiple timestamps for the same locations, collecting them is arguably cheaper than annotating them.
After all, many of us drive through the same routes every day (e.g. to and from work or school). Even when going to new places, the new routes for us are likely frequent for the local residents.
Concretely, whenever we discover multiple traversals of one route, we calculate a simple ephemerality statistic for each lidar point, which characterises the change of its local neighbourhood across traversals. We cluster lidar points according to their coordinates and ephemerality statistics. Resulting clusters with high ephemerality statistics, and located on the ground, are considered as mobile objects and are further fitted with upright bounding boxes.
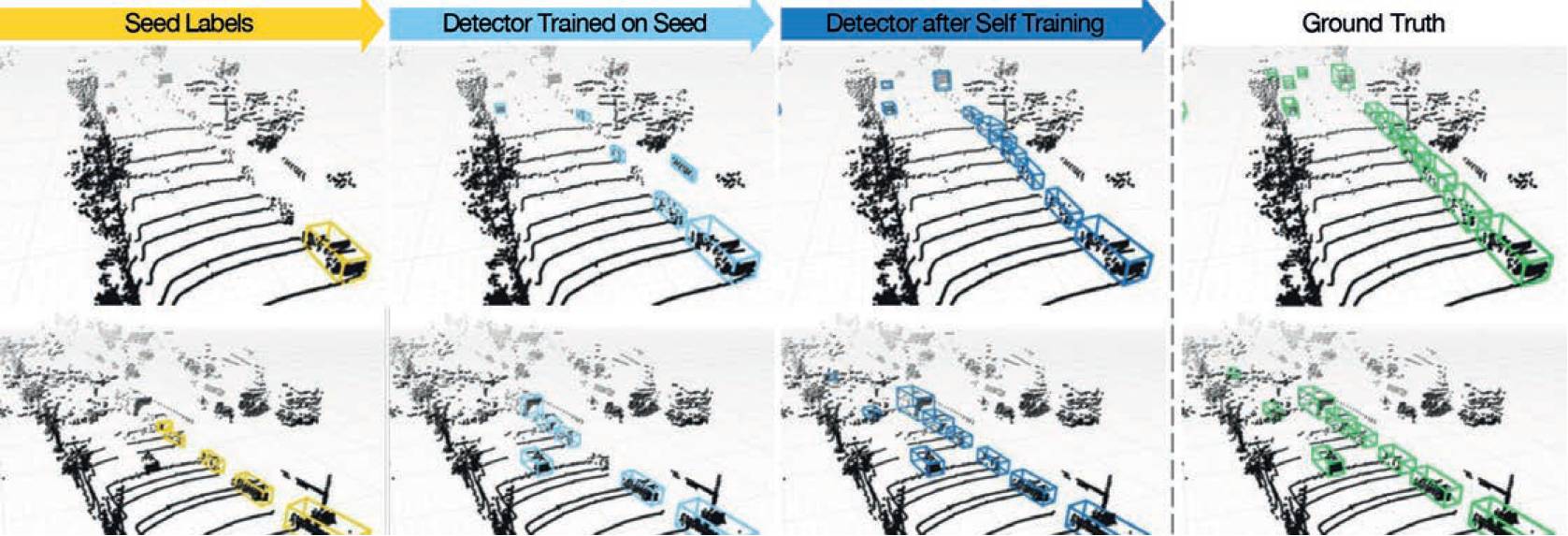
Figure 1– Visualisations of MODEST outputs. It shows lidar scans from two scenes in the Lyft dataset in two rows. From zero labels, the method is able to bootstrap a detector that achieves results close to the ground truth. The key insight is to utilise noisy 'seed’ labels produced from an ephemerality score and filtered with common-sense properties, and self-train upon them to obtain high quality results. Picture credit: Cornell University.
Self-training (ST)
While this initial seed set of mobile objects is not exhaustive (e.g. parked cars may be missed) and somewhat noisy in shape, we demonstrate that an object detector trained upon them can already learn the underlying object patterns and is able to output more and higher-quality bounding boxes than the seed set. This intriguing observation further opens up the possibility of using the detected object boxes as ‘better’ pseudo-ground truths to train a new object detector.
We show that such a self-training cycle enables the detector to improve itself over time; notably, it can even benefit from additional, unlabelled data that do not have multiple past traversals associated to them.
We validate our approach, MODEST (mobile object detection with ephemerality and self-training ) on the Lyft level 5 perception dataset and the nuScenes dataset with various types of detectors. We demonstrate that MODEST yields remarkably accurate mobile object detectors, comparable to their supervised counterparts.
Concretely, our contributions are three-fold:
- We propose a simple, yet effective approach to identifying ‘seed’ mobile objects from multiple traversals of lidar scans using zero labels.
- We show that using these seed objects, we can bootstrap accurate mobile object detectors via self-training.
- We evaluate our method exhaustively under various setting and demonstrate consistent performance across multiple real-world datasets.
Related works
We seek to build object detectors without any human supervision. We briefly discuss several related research areas.
3D object detection and existing datasets
Most existing 3D object detectors take 3D point clouds generated by lidar as input. They either consist of specialised neural architectures that can operate on point clouds directly or voxelise the point clouds to leverage 2D or 3D convolutional neural architectures. Regardless of the architectures, they are trained using supervision and their performances hinges directly on the training dataset.
However, the limited variety of objects and driving conditions in existing autonomous driving datasets impedes the generalisability of the resulting detectors. Generalising these to new domains requires a fresh labelling effort. In contrast, our unsupervised approach automatically discovers all the traffic participants, and can be used to train detectors in any new condition without any labelling.
Unsupervised object discovery in 2D/3D
Our work follows prior work on discovering objects both from 2D images as well as from 3D data. A first step in object discovery is to identify candidate objects, or ‘proposals’ from a single scene/ image. For 2D images, this is typically done by segmenting the image using appearance cues, but colour variations and perspective effects make this difficult. Tian et al exploits the correspondence between images and 3D point clouds to detect objects in 2D.
In 3D scenes, one can use 3D information such as surface normals. One can also use temporal changes such as motion. Our work combines effective 3D information with cues from changes in the scene over time to detect mobile objects.
In particular, similar to our approach, Herbst et al reconstruct the same scene at various times and carve out dissimilar regions as mobile objects. We use the analogous idea of ephemerality as proposed by Barnes et al.
We show in our work that this idea yields a surprisingly accurate set of initial objects. In addition, we also leverage other common-sense rules such as locations of the objects (e.g. objects should stay on the ground) or shapes of an object (e.g. objects should be compact).
However, crucially, we do not just stop at this proposal stage. Instead, we use these seed labels to train an object detector through multiple rounds of self-training. This effectively identifies objects consistent across multiple scenes. While previous work has attempted to use this consistency cue (including cosegmentation ) prior work typically uses clustering to accomplish this. In contrast, we demonstrate that neural network training and self-training provides a very strong signal and substantially improves the quality of the proposals or seed labels.
Self-training, semi-supervised and self-supervised learning
When training our detector, we use self-training, which has been shown to be highly effective for semi-supervised learning, domain adaptation and few-shot / transfer learning. Interestingly, we show that self-training can not only discover more objects, but also correct the initially noisy box labels. This result that neural networks can denoise noisy labels has been observed before. Self-training also bears resemblance to other semi-supervised learning techniques but is simpler and more broadly applicable.
Method
Problem setup
We want a detector that detects mobile objects, i.e. objects that might move, in lidar point clouds. We wish to train this detector only from unlabelled data obtained simply by driving around town, using a car equipped with synchronised sensors (in particular, lidar which provides 3D point clouds and GPS/INS which provides accurate estimates of vehicle position and orientation). Such a data collection scheme is practical and requires no annotators; indeed, it can be easily collected as people go about their daily lives. We assume that this unlabelled data include at least a few locations that have been visited multiple times; as we shall see, this provides us with a very potent learning signal for identifying mobile objects.
Overview
We propose simple, high-level commonsense properties that can easily identify a few seed objects in the unlabelled data. These discovered objects then serve as labels to train an off-the-shelf object detector. Specifically, building upon the neural network’s ability to learn consistent patterns from initial seed labels, we bootstrap the detector by self-training using the same unlabelled data.
The self-training process serves to correct and expand the initial pool of seed objects, gradually discovering more and more objects to further help train the detector.
1. Discovering objects through common-sense
What properties define mobile objects or traffic participants? Clearly, the most important characteristic is that they are mobile, i.e. they move around. If such an object is spotted at a particular location (e.g. a car at an intersection), it is unlikely that the object will still be there when one visits the intersection again a few days hence. In other words, mobile objects are ephemeral members of a scene. Of course, occasionally mobile objects like cars might be parked on the road for extended periods of time.
However, for the most part ephemeral objects are likely to be mobile objects. What other properties do mobile objects have? It is clear that they must be on the ground, not under the ground or above in the sky. They are also likely to be smaller than buildings. One can come up with more, but we find that these intuitive, common-sense properties serve as sufficient constraints for mining objects from unlabelled data.
Building upon these two sets of properties, we propose a bottom-up approach, which begins with identifying points that are ephemeral, followed by clustering them into seed objects that obey these common-sense properties. In the following sections, we discuss the implementations and visualise an example seed label generation.

Cornell researchers led by Kilian Weinberger, associate professor of computer science, have produced three recent papers on the ability of autonomous vehicles to use past traversals to 'learn the way' to familiar destinations. Picture credit: Ryan Young/Cornell University.
Identifying ephemeral points
We assume that our unlabelled data include a set of locations L which are traversed multiple times in separate driving sessions (or traversals). For every traversal t through location c ∈ L, we aggregate point clouds captured within a range of [– Hs s, He e ] of c to produce a dense 3D point cloud St t c for location c in traversal t1. We then use these dense point clouds St t c to define ephemerality as described by Barnes et al. Concretely, to check if a 3D point q in a scene is ephemeral, for each traversal t we can count the number Nt (q) of lidar points that fall within a distance r to q.
If q is part of the static background, then its local neighbourhood will look the same in all traversals, and so the counts Nt (q) will be all similar. Thus, we can check if q is ephemeral by checking if Nt (q) is approximately uniform across traversals.

Carlos Diaz-Ruiz, a doctoral student, drives the data collection car and demonstrates some of the data collection techniques the autonomous vehicle researchers use to create their algorithms. Picture credit: Ryan Young/Cornell University.
Here H(.) is the information entropy, T is the number of traversals through location c, and log (T) a normaliser to guarantee that T(q) ∈ [0, 1]2. A high PP score implies a high entropy of the distribution P ( .;q), which means that the counts Nt (q) over t are all similar, indicating that the point q is part of the static background.
From ephemeral points to ephemeral objects
We compute the PP score for each point in the lidar point clouds collected at a location c using multiple traversals. This automatically surfaces nonpersistent (and thus mobile) objects as blobs of points with low PP scores. We segment out these blobs automatically using the following straightforward clustering approach. First, we construct a graph whose vertices are points in the point cloud. The edges in the graph connect each point only to its mutual K-nearest neighbours in 3D within a distance r1. Each edge between points p and q is assigned a weight equal to the difference between their PP scores.

Picture credit: Ryan Young/Cornell University.
The graph structure together with the edge weights define a new metric that quantifies the similarity between two points. In this graph, two points that are connected by a path are considered to be close if the path has low total edge weight, namely, the points along the path share similar PP scores, indicating these points are likely from the same object. In contrast, a path in the graph that has high total edge weight likely goes across the boundary of two different objects (e.g. a mobile object and the background). Many graph-based clustering algorithms can fit the bill. We deploy the widely used DBSCAN algorithm for the clustering due to its simplicity and its ability to cluster without the need of setting the number of clusters beforehand.
DBSCAN returns a list of clusters, from which we remove clusters of static (and thus persistent) background points by applying a threshold γ on the ∝ percentile of PP scores in a cluster (i.e. remove the cluster if the ∝ percentile of the PP scores in this cluster is larger than γ). We then apply a straightforward bounding box fitting algorithm to fit an upright bounding box to each cluster.
Filtering using other common-sense properties
Finally, following our common-sense assumptions, we remove bounding boxes that are under the ground plane, floating in the air, or having exceptional large volume (see the supplementary). This produces the final set of seed pseudo-ground-truth bounding boxes for mobile objects.
Discussion
Our proposed procedure for object discovery, while intuitive and fully unsupervised, has several limitations. First, the bounding boxes are produced only for locations that were traversed multiple times. Second, owing to many filtering steps that we apply, these bounding boxes are not exhaustive. For example, parked cars along the side of the road might be marked as persistent and therefore may not be identified as mobile objects.
Finally, our heuristic box-fitting approach might fit inaccurate bounding boxes to noisy clusters that contain background points or miss foreground points. Thus in general, this initial set of seed bounding boxes might (a) miss many objects, and (b) produce incorrect box shapes and poses. Nevertheless, we find that this seed set has enough signal for training a high-quality mobile object detector, as we discuss below.
2. Bootstrapping a mobile object detector
Concretely, we simply take off-the-shelf 3D object detectors and directly train them from scratch on these initial seed labels via minimising the corresponding detection loss from the detection algorithms Intriguingly, the object detector trained in this way outperforms the original seed bounding boxes themselves – the ‘detected’ boxes have higher recall and are more accurate than the ‘discovered’ boxes on the same training point clouds (see Figure 1 for an illustration).
This phenomenon of a neural network improving on the provided noisy labels themselves is superficially surprising, but it has been observed before in other contexts. The key reason is that the noise is not consistent. The initial labels are generated scene-by-scene and object-by-object. In some scenes a car may be missed because it was parked throughout all traversals, while in many others it will be discovered as a mobile object.
Even among discovered boxes of similar objects, some may miss a few foreground points but others wrongly include background points. The neural network, equipped with limited capacity3, thus cannot reproduce this inconsistency and instead identifies the underlying consistent object patterns.
In particular, we find that the detector substantially improves recall; it is able to identify objects (like parked cars) that were missed in the ephemerality computation, because these seemingly static objects are nevertheless similar in shape to other moving objects identified as ephemeral. We also find many cases where the detector automatically corrects the box shape, based on the average box shape of similar objects it has encountered in the training data.
Finally, because the detector no longer needs multiple traversals, it can also find new mobile objects in scenes that were only visited once. In summary, this initial detector already discovers far more objects than the initial seed set and localises them more accurately.
Automatic improvement through self-training
Given that the trained detector has discovered many more objects, we can use the detector itself to produce an improved set of ground-truth labels, and re-train a new detector from scratch with these better ground truths. Furthermore, we can iterate this process: the new retrained detector has more positives and more accurate boxes for training, so it will likely have higher recall and better localisation than the initial detector. As such we can use this second detector to produce a new set of pseudo-ground-truth boxes which can be used to train a third detector and so on. This iterative self-training process will eventually converge when the pseudo-ground truth labelling is consistent with itself and the detector can no longer improve upon it.
While it is possible for this iterative self-training to cause concept drift (e.g. the detector reinforces from its error), we find empirically that a simple thresholding step similar to that in subsubsection ‘From ephemeral points to ephemeral objects’ – remove the pseudo-ground- truth box if the › percentile of the PP scores within the box is larger than › – is highly effective in removing false positives (hence improve precision) in the self-training process and prevents performance degradation.
Experiments
Datasets
We validate our approach on two datasets: Lyft Level 5 Perception and nuScenes. To the best of our knowledge, these are the only two publicly available autonomous driving datasets that have both bounding box annotations and multiple traversals with accurate localisation. To ensure fair assessment of generalisability, we re-split the dataset so that the training set and test set are geographically disjoint; we also discard locations with less than two examples in the training set. This results a train/test split of 11,873/4,901 point clouds for Lyft and 3,985/2,324 for nuScenes. To construct ground truth labels, we group all the traffic participant types in the original datasets into a single ‘mobile’ object. Note that the ground-truth labels are only used for evaluation, not training.
In addition, we convert the raw Lyft and nuScenes data into the KITTI format to leverage off-the-shelf 3D object detectors that is predominantly built for KITTI. We use the roof lidar (40 or 60 beam in Lyft; 32 beam in nuScenes), and the global 6-DoF localisation along with the calibration matrices directly from the raw data.
On localisation
With current localisation technology, we can reliably achieve accurate localisation (e.g. 1-2cm-level accuracy with RTK4, 10cm-level with Monte Carlo Localisation scheme as adopted in the nuScenes dataset. We assume good localisation in the training set.
Evaluation metric
We follow KITTI to evaluate object detection in the bird’s-eye view (BEV) and in 3D for the mobile objects. We report average precision (AP) with the intersection over union (IoU) thresholds at 0.5/0.25, which are used to evaluate cyclists and pedestrian objects in KITTI. We further follow to evaluate the AP at various depth ranges.
Implementation
We present results on PointRCNN (the conclusions hold for other detectors such as PointPillars, and VoxelNet (SECOND). See more details in the supplementary materials). For reproducibility, we use the publicly available code from OpenPCDet for all models. We use the default hyperparameters tuned for KITTI except on the Lyft dataset in which we enlarge the perception range from 70m to 90m (since Lyft provides labels beyond 70m) and reduce the number of training epochs by 1/4 (since the training set is about three times of the size of KITTI). We default to 10 rounds of selftraining (chosen arbitrarily due to compute constraints) and trained the model from scratch for each round of self-training.
We also include results on PointRCNN trained up to 40 rounds, where we empirically observe that the performance converges. All models are trained with 4 NVIDIA 3090 GPUs.
Baselines and ablations
We are the first work to train object detectors without any labels at all, and as such no previously published baselines exist. We create baselines by ablating the two key components of our model; seed labels generation via multiple traversals and repeated self-training:
- MODEST-PP (R0): This is a detector trained with seed labels generated without leveraging the multiple traversals. The seed labels are constructed by the exact same process as described in the ‘method’ section, except we replace the edge weights in one by spatial proximity: w(e q,p) = ∥q p∥2 and change ∈ to 1.0 in DBSCAN, and do not perform any PP-score-based filtering on the clusters generated by DBSCAN. No repeated self-training is performed for this baseline.
- MODEST-PP (Ri): This detector is trained similarly to the previous baseline except we repeat i rounds of self-training without using PP-score-based filtering.
- MODEST (R0): This detector is trained with the seed labels without repeated self-training.
Detecting mobile objects without annotations
We present results on Lyft and observe that:
- Object detectors can be trained using unlabelled data. We observe that our approach yields accurate detectors, especially for the 0-50m range. For this range, MODEST is competitive with the fully supervised model trained on Lyft, and in fact outperforms a model trained with ground-truth supervision on KITTI. This suggests that MODEST is especially useful for bootstrapping recognition models in new domains.
- Our initial seed labels suffices to train a detector. Detectors learned from our initial seed (MODEST (R0)) achieve more than 50% of supervised performance for nearby objects, suggesting that our common-sense cues do produce a good initial training set. We also investigated the quality of the seed labels.
- Repeated self-training significantly improves performance. We observe that if the seed labels can provide enough signals for training a decent detector, self-training can further drastically boost the performance, for example, by more than 500% from 8.9 to 47.1 on APBEV IoU=0.25 on 50-80m range.
- Ephemerality is a strong training signal. We observe MODEST unanimously outperform MODEST-PP by a significant margin.
We note that this performance of our detectors is especially good considering that we are evaluating it on predicting the full amodal extent of the bounding box, even though it has only seen the visible extent of the objects in the data. We notice that because of this discrepancy, our model produces smaller boxes; a size adjustment might well substantially improve accuracy for higher overlap thresholds.
We apply our approach in nuScenes dataset without changing the hyperparameters. The above conclusions still hold. Notice that when we remove ephemerality (MODESTPP(R10)), we are not able to extract enough signals to train a decent detector on nuScenes where lidar is much sparser than Lyft.
Cross-domain evaluation
It is possible that our automatic labelling process and multiple rounds of self-training overfit to biases in the training domain. To see if this is the case, we test whether our models trained on unlabelled data from Lyft generalise to KITTI. We observe that our detectors are still just as competitive with supervised detectors especially on close to middle ranges.
Analysis
Given the good performance of our detectors, we dig deeper into the individual components to identify the key contributors to success.
Analysis on the PP score
In MODEST, PP score plays a critical role of distinguishing stationary points from stationary, background points. As such, we can plot the histogram of PP score for non-stationary and stationary points in the train split of the Lyft dataset. Nonstationary points are defined as the points within labelled bounding boxes for mobile objects, while background points are the points outside of these bounding boxes. The histogram shows that for background points the PP score highly concentrates around 1, while for non-stationary points the score is much lower.
Effect of different amount of unlabelled data
Customary to any unsupervised learning algorithm, we investigate how different amount of unlabelled data affects our algorithm. We randomly subsampled our training set and reported the performance of MODEST and across all ranges, we observed a general upward trend with more unlabelled data available. These results suggest that MODEST only needs a small amount of data to identify the rough location of mobile objects (evaluation at lower IoU is more lenient towards localisation errors) and can significantly improve localisation with more data.
Quality of training labels
The quality of the detector is determined by the quality of the automatically generated training labels. We evaluated the generated pseudo-ground truth boxes by computing their precision and recall compared to the ground truth. For seed labels, compared with MODEST-PP, PP score yields a set of labels with much higher precision but lower recall due to the filtering process.
This is in line with our intuition that these seed boxes are conservative but high quality. After one round of training, the generated boxes have higher recall and precision. Subsequent rounds of self-training substantially improves recall especially on the far range, affirming our intuition that the neural network slowly identifies missed objects that are consistent with the conservative training sets. Put together, the whole process boosts the overall precision of seed labels by almost 40% and nearly doubles overall recall. This improved training data is reflected in the improvement in detector performance with self-training.

Video still of the technology. Credit: Ryan Young/Cornell University.
Effect of different rounds of self-training
Given that self-training substantially improves the quality of the training labels, we next look at how this impacts the detector. We have been able to show how APBEV changes with different rounds of self-training. We observe that performance can improve for up to 40 rounds of self-training with larger amount of data (›50%). Although more rounds can improve the performance, we emphasise that the improvement brought by PP score filtering cannot be compensated by additional rounds of self-training (the 100% line).
Maximum achievable recall by object types
We further evaluated the maximum achievable recall of the different object types in the Lyft test set for various methods. We combine the other_vehicle, truck, bus, emergency_vehicle in the raw Lyft dataset into the truck type and the motorcycle, bicycle into the cyclist type. It can be seen that MODEST detects not only dominant, large objects in the dataset (car), but also less common, smaller objects (pedestrian and cyclist).
Common-sense vs. self-training. Clearly both our common-sense-based seed boxes and our self-training approach are crucial for detector accuracy. But how do they stack against each other? We attempted to trade-off the seed labels vs. the self-training by varying the number of scenes available to each step.
We also experimented with switching off common-sense-based (i.e. PP score-based) filtering during self-training. We observe that increasing the number of scenes for self-training has a bigger impact than increasing the size of the seed set. Interestingly, without PP score-based filtering, using 100% data for seed labels performs worse than using only 5% of the scenes.
This may be because if all scenes are used for seed label computation and then used for training the detector, the detector may over-fit to the quirks of these labels and may not be able to correct them during self-training. Having a ‘held-out’ set of scenes for self-training thus seems beneficial. We also observe that PP scorebased filtering does have a big impact on self-training and improves performance significantly. Thus common-sense-based filtering is crucial even within the self-training pipeline, suggesting a synergy between common-sense and neural net training.
Qualitative results
We have been able to show qualitative results of ‘seed’ label generation and provide a visualisation of self-training on two scenes in Figure 1 on the ‘train’ split of the Lyft dataset. Observe that the seed label generation filters out many of the superfluous clusters, but occasionally misses some objects or produces incorrectly sized objects. Via bootstrapping an object detector, our method can gradually recover the shape of mobile objects, as well as obtain higher.
Discussion
Limitation
Our approach focuses on learning to detect mobile objects and is evaluated by IoU between detections and ground-truth bounding boxes with single object type. We do not take the heading of objects into account, nor do we classify different object types. Also as mentioned above, our model tends to produce smaller boxes rather than amodal boxes. We leave these as future work.
Conclusion
In this work, we explore a novel problem of learning a 3D mobile object detector from lidar scans without any labels. Though this seems impossible at the first glance, we propose MODEST and show that with simple heuristics about mobile objects, e.g. they are not persistent over time, we can generate weak labels and bootstrap a surprisingly accurate detector from them. We evaluate MODEST exhaustively on two large-scale, real-world datasets and draw consistent conclusions.
We consider our work a first step towards a larger research effort to make entirely unsupervised object detectors a highly competitive reality. The potential impact of such an achievement would be monumental, allowing cars to be re-trained while in use, adapting to their local environments, enabling reliable driver assist and self-driving vehicles in developing countries, and avoiding privacy concerns by training vehicles on their own locally gathered data.
We hope our work will inspire more research into this new and highly relevant problem.
Yurong You, Katie Luo, Cheng Perng Phoo, Wen Sun, Bharath Hariharan, Mark Campbell and Kilian Q. Weinberger, Cornell University, and Wei-Lun Chao, The Ohio State University
For the complete paper, which includes all the tables, equations, images and data, visit https://arxiv.org/pdf/2203.15882.pdf
Acknowledgements: This research is supported by grants from the National Science Foundation NSF (III-1618134, III-1526012, IIS-1149882, IIS-1724282, TRIPODS-1740822, IIS-2107077, OAC-2118240, OAC2112606 and IIS-2107161), the Office of Naval Research DOD (N00014-17-1-2175), the DARPA Learning with Less Labels programme (HR001118S0044), the Bill and Melinda Gates Foundation, the Cornell Centre for Materials Research with funding from the NSF MRSEC program (DMR-1719875), and SAP America.
---
1 We can easily transform captured point clouds to a shared coordinate frame via precise localisation information through GPS/INS.
2 The KL divergence between P and the uniform distribution f(t) =1/T is KL(P(t;q)›f(t)) = log(T) - H (P(t;q)) and high entropy implies large similarity with the uniform distribution.
3 We note that for detection problems, a neural network can hardly overfit the training data to achieve 100% accuracy, in contrast to classification problems.
4 https://en.wikipedia.org/wiki/Real-time_kinematic_positioning.